Real Estate Web Design - Information
|
- The following are various research papers including the famed page rank and anatomy of large-scale hypertextual search engines paper by Surgey Brin and Lawrence Page.� This reading is quite advanced but if nothing else with your fill for the terminology used in the SCO world
The Anatomy of a Large-Scale Hypertextual Web Search Engine
(1998
), by Sergey Brin and Lawrence Page (Stanford University)
- In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/. To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date. Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
The PageRank Citation Ranking: Bringing Order to the Web
.
(1999) by Lawence Page, Sergey Brin, Rajeeve Motwani, Terry Winograd.( Stanford University
)
- The importance of a Web page is an inherently subjective matter, which depends on the readers interests, knowledge and attitudes. But there is still much that can be said objectively about the relative importance of Web pages. This paper describes PageRank, a mathod for rating Web pages objectively and mechanically, effectively measuring the human interest and attention devoted to them. We compare PageRank to an idealized random Web surfer. We show how to efficiently compute PageRank for large numbers of pages. And, we show how to apply PageRank to search and to user navigation.
MapReduce: Simplified Data Processing on Large Clusters
(2004
) Jeffrey Dean and Sanjay Ghemawat, Google, Inc.
- �
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a _map_ function that processes a key/value pair to generate a set of intermediate key/value pairs, and a _reduce_ function that merges all intermediate values associated with the same intermediate key. Many real world tasks are expressible in this model, as shown in the paper.
(Note: this is a program that Google uses to recompile its index in addition to other tasks)
- The Google File System
(2003
), by Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Google)
- We have designed and implemented the Google File System, a scalable distributed file system for large distributed data-intensive applications. It provides fault tolerance while running on inexpensive commodity hardware, and it delivers high aggregate performance to a large number of clients. While sharing many of the same goals as previous distributed file systems, our design has been driven by observations of our application workloads and technological environment, both current and anticipated, that reflect a marked departure from some earlier file system assumptions. This has led us to reexamine traditional choices and explore radically different design points. The file system has successfully met our storage needs. It is widely deployed within Google as the storage platform for the generation and processing of data used by our service as well as research and development efforts that require large data sets. The largest cluster to date provides hundreds of terabytes of storage across thousands of disks on over a thousand machines, and it is concurrently accessed by hundreds of clients. In this paper, we present file system interface extensions designed to support distributed applications, discuss many aspects of our design, and report measurements from both micro-benchmarks and real world use.
-
-
We investigate using gradient descent methods for learning ranking functions; we propose a simple probabilistic cost function and we introduce RankNet, an implementation of these ideas using a neural network to model the underlying ranking function. We present test results on toy data and on data from a commercial internet search engine.
-
- Patterns in Unstructured Data
(2003
), by Clara Yu, John Cuadrado, Maciej Ceglowski, J. Scott Payne (National Institute for Technology and Liberal Education)
- The need for smarter search engines is a presentation suggesting several methods of improving search engine relevancy including latent semantic indexing and multi-dimensional scalining.
-
- When Experts Agree: Using Non-Affiliated Experts to Rank Popular Topics
(2000
), by Krishna Bharat, George A. Mihaila (Google)
- In response to a query a search engine returns a ranked list of documents. If the query is on a popular topic (i.e., it matches many documents) then the returned list is usually too long to view fully. Studies show that users usually look at only the top 10 to 20 results. However, the best targets for popular topics are usually linked to by enthusiasts in the same domain which can be exploited. In this paper, we propose a novel ranking scheme for popular topics that places the most authoritative pages on the query topic at the top of the ranking. Our algorithm operates on a special index of "expert documents." These are a subset of the pages on the WWW identified as directories of links to non-affiliated sources on specific topics. Results are ranked based on the match between the query and relevant descriptive text for hyperlinks on expert pages pointing to a given result page. We present a prototype search engine that implements our ranking scheme and discuss its performance. With a relatively small (2.5 million page) expert index, our algorithm was able to perform comparably on popular queries with the best of the mainstream search engines.
- Authoritative Sources in a Hyperlinked Environment
(1997
), by Jon M. Kleinberg (Cornell)
- The network structure of a hyperlinked environment can be a rich source of in- formation about the content of the environment, provided we have e ective means for understanding it. We develop a set of algorithmic tools for extracting information from the link structures of such environments, and report on experiments that demonstrate their e ectiveness in a variety of contexts on the World Wide Web. The central issue we address within our framework is the distillation of broad search topics, through the discovery of "authoritative" information sources on such topics. We propose and test an algorithmic formulation of the notion of authority, based on the relationship between a set of relevant authoritative pages and the set of" hub pages" that join them together in the link structure. Our formulation has connections to the eigenvectors of certain matrices associated with the link graph; these connections in turn motivate additional heuristics for link-based analysis.
Combatting Webspam with Trustrank
(2005
) by Zoltna Gyongi (Stanford) Hector Garcia-Molina (Stanford) Jan Pedersen (Yahoo)
- Web spam uses various techniques to achieve higher-than-deserved rankings in a search engines result. While human experts can indentify spam, its too expensive to Manually evaluate a large number of pages. Instead we propose techniques to semi-automatically seperate reputable, good pages from spam. We first select a small set of seed pages to be evaluated by an expert. Once we manually identify the reputable seed pages we use the linking structure of the web to discover other pages that are likely to be good...
Our results show that we can effectively filter out spam from a significant fraction of the web, based on a good seed set of less than 200 sites.
-
- SearchPad: Explicit Capture of Search Context to Support Web Search
(2000
), by Krishna Bharat (Google)
- Experienced users who query search engines have a complex behavior. They explore many topics in parallel, experiment with query variations, consult multiple search engines, and gather information over many sessions. In the process they need to keep track of search context -- namely useful queries and promising result links, which can be hard. We present an extension to search engines called SearchPad that makes it possible to keep track of "search context" explicitly. We describe an efficient implementation of this idea deployed on four search engines: AltaVista, Excite, Google and Hotbot. Our design of SearchPad has several desirable properties: (i) portability across all major platforms and browsers, (ii) instant start requiring no code download or special actions on the part of the user, (iii) no server side storage, and (iv) no added client-server communication overhead. An added benefit is that it allows search services to collect valuable relevance information about the results shown to the user. In the context of each query SearchPad can log the actions taken by the user, and in particular record the links that were considered relevant by the user in the context of the query. The service was tested in a multi-platform environment with over 150 users for 4 months and found to be usable and helpful. We discovered that the ability to maintain search context explicitly seems to affect the way people search. Repeat SearchPad users looked at more search results than is typical on the web, suggesting that availability of search context may partially compensate for non relevant pages in the ranking.
- Improved Algorithms for Topic Distillation in a Hyperlinked Environment
(1998
), by Krishna Bharat, Monika R. Henzinger (Now at Google)
- This paper addresses the problem of topic distillation on theWorld WideWeb, namely, given a typical user query to find quality documents related to the query topic. Connectivity analysis has been shown to be useful in identifying high quality pages within a topic specific graph of hyperlinked documents. The essence of our approach is to augment a previous connectivity analysis based algorithm with content analysis. We identify three problems with the existing approach and devise algorithms to tackle them. The results of a user evaluation are reported that show an improvement of precision at 10 documents by at least 45% over pure connectivity analysis.
- Ranking Search Results By Reranking the Results Based on Local Inter-Connectivity
(2003
), by Krishna Bharat (Google)
- A search engine for searching a corpus improves the relevancy of the results by refining a standard relevancy score based on the interconnectivity of the initially returned set of documents. The search engine obtains an initial set of relevant documents by matching a user's search terms to an index of a corpus. A re-ranking component in the search engine then refines the initially returned document rankings so that documents that are frequently cited in the initial set of relevant documents are preferred over documents that are less frequently cited within the initial set.
- Adaptive Methods for the Computation of PageRank
(2002
), by Sepandar Kamvar, Taher Haveliwala, Gene Golub (Stanford University)
- We observe that the convergence patterns of pages in the PageRank algorithm have a nonuniform distribution. Specifically, many pages converge to their true PageRank quickly, while relatively few pages take a much longer time to converge. Furthermore, we observe that these slow-converging pages are generally those pages with high PageRank. We use this observation to devise a simple algorithm to speed up the computation of PageRank, in which the PageRank of pages that have converged are not recomputed at each iteration after convergence. This algorithm, which we call Adaptive PageRank, speeds up the computation of PageRank by nearly 30%.
- Exploiting the Block Structure of the Web for Computing PageRank
(2003
), by Sepandar Kamvar, Taher Haveliwala, Chris Manning, and Gene Golub (Stanford University)
- The web link graph has a nested block structure: the vast majority of hyperlinks link pages on a host to other pages on the same host, and many of those that do not link pages within the same domain. We show how to exploit this structure to speed up the computation of PageRank by a 3-stage algorithm whereby (1) the local Page- Ranks of pages for each host are computed independently using the link structure of that host, (2) these local PageRanks are then weighted by the �importance� of the corresponding host, and (3) the standard PageRank algorithm is then run using as its starting vector the weighted aggregate of the local PageRanks. Empirically, this algorithm speeds up the computation of PageRank by a factor of 2 in realistic scenarios. Further, we develop a variant of this algorithm that effi- ciently computes many different personalized PageRanks, and a variant that efficiently recomputes PageRank after node updates.
- Extrapolation Methods for Accelerating PageRank Computations
(2003
), by Sepandar Kamvar, Taher Haveliwala, Chris Manning, and Gene Golub (Stanford University)
- We present a novel algorithm for the fast computation of PageRank, a hyperlink-based estimate of the importance of Web pages. The original PageRank algorithm uses the Power Method to compute successive iterates that converge to the principal eigenvector of the Markov matrix representing the Web link graph. The algorithm presented here, called Quadratic Extrapolation, accelerates the convergence of the Power Method by periodically subtracting off estimates of the nonprincipal eigenvectors from the current iterate of the Power Method. In Quadratic Extrapolation, we take advantage of the fact that the first eigenvalue of a Markov matrix is known to be 1 to compute the nonprincipal eigenvectors using successive iterates of the Power Method. Empirically, we show that using Quadratic Extrapolation speeds up PageRank computation by 25 300% on aWeb graph of 80 million nodes, with minimal overhead. Our contribution is useful to the PageRank community and the numerical linear algebra community in general, as it is a fast method for determining the dominant eigenvector of a matrix that is too large for standard fast methods to be practical.
- Building a Distributed Full-Text Index for the Web
(2001
), by Sergey Melnik, Sriram Raghavan, Beverly Yang, Hector Garcia-Molina (Stanford University)
- We identify crucial design issues in building a distributed inverted index for a large collection of Web pages. We introduce a novel pipelining technique for structuring the core index-building system that substantially reduces the index construction time. We also propose a storage scheme for creating and managing inverted files using an embedded database system. We suggest and compare different strategies for collecting global statistics from distributed inverted indexes. Finally, we present performance results from experiments on a testbed distributed indexing system that we have implemented.
- Dynamic Data Mining: Exploring Large Rule Spaces by Sampling
(1999
), by Sergey Brin, Lawrence Page (Stanford University)
- A great challenge for data mining techniques is the huge space of potential rules which can be generated. If there are tens of thousands of items, then potential rules involving three items number in the trillions. Traditional data mining techniques rely on downward-closed measures such as support to prune the space of rules. However, in many applications, such pruning techniques either do not sufficiently reduce the space of rules, or they are overly restrictive. We propose a new solution to this problem, called Dynamic Data Mining (DDM). DDM foregoes the completeness offered by traditional techniques based on downward-closed measures in favor of the ability to drill deep into the space of rules and provide the user with a better view of the structure present in a data set. Instead of a single deterministic run, DDM runs continuously, exploring more and more of the rule space. Instead of using a downward-closed measure such as support to guide its exploration, DDM uses a user-defined measure called weight, which is not restricted to be downward closed. The exploration is guided by a heuristic called the Heavy Edge Property. The system incorporates user feedback by allowing weight to be redefined dynamically. We test the system on a particularlly difficult data set - the word usage in a large subset of the World Wide Web. We find that Dynamic Data Mining is an effective tool for mining such difficult data sets.
- Computing Iceberg Queries Efficiently
(1999
), by Min Fang, Narayanan Shivakumar, Hector Garcia-Molina, Rajeev Motwani, Jeffrey D. Ullman (Stanford University)
- Many applications compute aggregate functions (such as COUNT, SUM) over an attribute (or set of attributes) to find aggregate values above some specified threshold. We call such queries iceberg queries because the number of above-threshold results is often very small (the tip of an iceberg), relative to the large amount of input data (the iceberg). Such iceberg queries are common in many applications, including data warehousing, information-retrieval, market basket analysis in data mining, clustering and copy detection. We propose efficient algorithms to evaluate iceberg queries using very little memory and significantly fewer passes over data, as compared to current techniques that use sorting or hashing. We present an experimental case study using over three gigabytes of Web data to illustrate the savings obtained by our algorithms.
- Extracting Patterns and Relations from the World Wide Web
(1999
), by Sergey Brin (Stanford University)
- The World Wide Web is a vast resource for information. At the same time it is extremely distributed. A particular type of data such as restaurant lists may be scattered across thousands of independent information sources in many different formats. In this paper, we consider the problem of extracting a relation for such a data type from all of these sources automatically. We present a technique which exploits the duality between sets of patterns and relations to grow the target relation starting from a small sample. To test our technique we use it to extract a relation of (author, title) pairs from the World Wide Web.
�
- Finding Near-Replicas of Documents on the Web
(1998
), by Narayanan Shivakumar, Hector Garcia-Molina (Stanford University)
-
- We consider how to effciently compute the overlap between all pairs of web documents. This information can be used to improve web crawlers, web archivers and in the presentation of search results, among others. We report statistics on how common replication is on the web, and on the cost of computing the above information for a relatively large subset of the web { about 24 million web pages which corresponds to about 150 Gigabytes of textual information.
-
- Where Have You Been? A Comparison of Three Web Tracking Technologies
(1999
), by Onn Brandman, Hector Garcia-Molina, and Andreas Paepcke (Stanford University)
- Web searching and browsing can be improved if browsers and search engines know which pages users frequently visit. 'Web tracking' is the process of gathering that information. The goal for Web tracking is to obtain a database describing Web page download times and users' page traversal patterns. The database can then be used for data mining or for suggesting popular or relevant pages to other users. We implemented three Web tracking systems, and compared their performance. In the first system, rather than connecting directly to Web sites, a client issues URL requests to a proxy. The proxy connects to the remote server and returns the data to the client, keeping a log of all transactions. The second system uses "sniffers" to log all HTTP traffic on a subnet. The third system periodically collects browser log files and sends them to a central repository for processing. Each of the systems differs in its advantages and pitfalls. We present a comparison of these techniques.
�
- Crawler-Friendly Web Servers
(2000
), by Onn Brandman, Hector Garcia-Molina, and Andreas Paepcke (Stanford University)
- In this paper we study how to make web servers (e.g., Apache) more crawler friendly. Current web servers offer the same interface to crawlers and regular web surfers, even though crawlers and surfers have very different performance requirements. We evaluate simple and easy-to-incorporate modifications to web servers so that there are significant bandwidth savings. Specifically, we propose that web servers export meta-data archives decribing their content.
- �
- Exploiting Geographical Location Information of Web Pages
(1999
), by Orkut Buyukokkten, Junghoo Cho, Hector Garcia-Molina, Luis Gravano, and Narayanan Shivakumar (Stanford University)
- Many information sources on the web are relevant primarily to specific geographical communities. For instance, web sites containing information on restaurants, theatres and apartment rentals are relevant primarily to web users in geographical proximity to these locations. We make the case for identifying and exploiting the geographical location information of web sites so that web applications can rank information in a geographically sensitive fashion. For instance, when a user in Palo Alto issues a query for "Italian Restaurants," a web search engine can rank results based on how close such restaurants are to the user's physical location rather than based on traditional IR measures. In this paper, we first consider how to compute the geographical location of web pages. Subsequently, we consider how to exploit such information in one specific "proof-of-concept" application we implemented in JAVA.
�
- Collaborative value filtering on the Web
(2000
), by Andreas Paepcke, Hector Garcia-Molina, and Gerard Rodriquez (Stanford University)
- Today's Internet search engines help users locate information based on the textual similarity of a query and potential documents. Given the large number of documents available, the user often finds too many documents, and even if the textual similarity is high, in many cases the matching documents are not relevant or of interest. Our goal is to explore other ways to decide if documents are "of value" to the user, i.e., to perform what we call "value filtering." In particular, we would like to capture access information that may tell us-within limits of privacy concerns-which user groups are accessing what data, and how frequently. This information can then guide users, for example, helping identify information that is popular, or that may have helped others before. This is a type of collaborative filtering or community-based navigation. Access information can either be gathered by the servers that provide the information, or by the clients themselves. Tracing accesses at servers is simple, but often information providers are not willing to share this information. We therefore are exploring client-side gathering. Companies like Alexa are currently using client gathering in the large. We are studying client gathering at a much smaller scale, where a small community of users with shared interest collectively track their information accesses. For this, we have developed a proxy system called the Knowledge Sharing System (KSS) that monitors the behavior of a community of users. Through this system we hope to: 1. Develop mechanisms for sharing browsing expertise among a community of users; and 2. Better understand the access patterns of a group of people with common interests, and develop good schemes for sharing this information.
�
- Beyond Document Similarity: Understanding Value-Based Search and Browsing Technologies
(2000
), by Andreas Paepcke, Hector Garcia-Molina, Gerard Rodriguez, and Junghoo Cho
- In the face of small, one or two word queries, high volumes of diverse documents on the Web are overwhelming search and ranking technologies that are based on document similarity measures. The increase of multimedia data within documents sharply exacerbates the shortcomings of these approaches. Recently, research prototypes and commercial experiments have added techniques that augment similarity-based search and ranking. These techniques rely on judgments about the 'value' of documents. Judgments are obtained directly from users, are derived by conjecture based on observations of user behavior, or are surmised from analyses of documents and collections. All these systems have been pursued independently, and no common understanding of the underlying processes has been presented. We survey existing value-based approaches, develop a reference architecture that helps compare the approaches, and categorize the constituent algorithms. We explain the options for collecting value metadata, and for using that metadata to improve search, ranking of results, and the enhancement of information browsing. Based on our survey and analysis, we then point to several open problems.
-
- Searching the Web
(2001
), by Arvind Arasu, Junghoo Cho, Hector Garcia-Molina, Andreas Paepcke, and Sriram Raghavan (Stanford University)
- We offer an overview of current Web search engine design. After introducing a generic search engine architecture, we examine each engine component in turn. We cover crawling, local Web page storage, indexing, and the use of link analysis for boosting search performance. The most common design and implementation techniques for each of these components are presented. We draw for this presentation from the literature, and from our own experimental search engine testbed. Emphasis is on introducing the fundamental concepts, and the results of several performance analyses we conducted to compare different designs.
- Efficient Crawling Through URL Ordering
(1998
), by Junghoo Cho, Hector Garcia-Molina, Lawrence Page (Stanford University)
- In this paper we study in what order a crawler should visit the URLs it has seen, in order to obtain more "important" pages first. Obtaining important pages rapidly can be very useful when a crawler cannot visit the entire Web in a reasonable amount of time. We define several importance metrics, ordering schemes, and performance evaluation measures for this problem. We also experimentally evaluate the ordering schemes on the Stanford University Web. Our results show that a crawler with a good ordering scheme can obtain important pages significantly faster than one without.
�
- Estimating Frequency of Change
(2000
), by Junghoo Cho, Hector Garcia-Molina (Stanford University)
- Many online data sources are updated autonomously and independently. In this paper, we make the case for estimating the change frequency of the data, to improve web crawlers, web caches and to help data mining. We first identify various scenarios, where different applications have different requirements on the accuracy of the estimated frequency. Then we develop several "frequency estimators" for the identified scenarios. In developing the estimators, we analytically show how precise/effective the estimators are, and we show that the estimators that we propose can improve precision significantly.
�
- Finding Replicated Web Collections
(2000
), by Junghoo Cho, N. Shivakumar, and Hector Garcia-Molina (Stanford University)
- Many web documents (such as JAVA FAQs) are being replicated on the Internet. Often entire document collections (such as hyperlinked Linux manuals) are being replicated many times. In this paper, we make the case for identifying replicated documents and collections to improve web crawlers, archivers, and ranking functions used in search engines. The paper describes how to efficiently identify replicated documents and hyperlinked document collections. The challenge is to identify these replicas from an input data set of several tens of millions of web pages and several hundreds of gigabytes of textual data. We also present two real-life case studies where we used replication information to improve a crawler and a search engine. We report these results for a data set of 25 million web pages (about 150 gigabytes of HTML data) crawled from the web.
�
- Parallel Crawlers
(2002
), by Junghoo Cho, Hector Garcia-Molina (Stanford University)
- In this paper we study how we can design an effective parallel crawler. As the size of the Web grows, it becomes imperative to parallelize a crawling process, in order to finish downloading pages in a reasonable amount of time. We first propose multiple architectures for a parallel crawler and identify fundamental issues related to parallel crawling. Based on this understanding, we then propose metrics to evaluate a parallel crawler, and compare the proposed architectures using 40 million pages collected from the Web. Our results clarify the relative merits of each architecture and provide a good guideline on when to adopt which architecture.
�
- The Evolution of the Web and Implications for an Incremental Crawler
(2000
), by Junghoo Cho, Hector Garcia-Molina (Stanford University)
- In this paper we study how to build an effective incremental crawler. The crawler selectively and incrementally updates its index and/or local collection of web pages, instead of periodically refreshing the collection in batch mode. The incremental crawler can improve the ``freshness'' of the collection significantly and bring in new pages in a more timely manner. We first present results from an experiment conducted on more than half million web pages over 4 months, to estimate how web pages evolve over time. Based on these experimental results, we compare various design choices for an incremental crawler and discuss their trade-offs. We propose an architecture for the incremental crawler, which combines the best design choices.
�
- Synchronizing a Database to Improve Freshness
(2000
), by Junghoo Cho, Hector Garcia-Molina (Stanford University)
- In this paper we study how to refresh a local copy of an autonomous data source to maintain the copy up-to-date. As the size of the data grows, it becomes more difficult to maintain the copy "fresh," making it crucial to synchronize the copy effectively. We define two freshness metrics, change models of the underlying data, and synchronization policies. We analytically study how effective the various policies are. We also experimentally verify our analysis, based on data collected from 270 web sites for more than 4 months, and we show that our new policy improves the "freshness" very significantly compared to current policies in use.
�
- Efficient Computation of PageRank
(1999
), by Taher Haveliwala (Stanford University)
- This paper discusses efficient techniques for computing PageRank, a ranking metric for hypertext documents. We show that PageRank can be computed for very large subgraphs of the web (up to hundreds of millions of nodes) on machines with limited main memory. Running-time measurements on various memory configurations are presented for PageRank computation over the 24-million-page Stanford WebBase archive. We discuss several methods for analyzing the convergence of PageRank based on the induced ordering of the pages. We present convergence results helpful for determining the number of iterations necessary to achieve a useful PageRank assignment, both in the absence and presence of search queries.
�
- Evaluating Strategies for Similarity Search on the Web
(2002
), by Taher Haveliwala, Aristides Gionis, Dan Klein, and Piotr Indyk (Stanford University)
- Finding pages on the Web that are similar to a query page (Related Pages) is an important component of modern search engines. A variety of strategies have been proposed for answering Related Pages queries, but comparative evaluation by user studies is expensive, especially when large strategy spaces must be searched (e.g., when tuning parameters). We present a technique for automatically evaluating strategies using Web hierarchies, such as Open Directory, in place of user feedback. We apply this evaluation methodology to a mix of document representation strategies, including the use of text, anchor-text, and links. We discuss the relative advantages and disadvantages of the various approaches examined. Finally, we describe how to efficiently construct a similarity index out of our chosen strategies, and provide sample results from our index.
�
- Scalable Techniques for Clustering the Web
(2000
), by Taher Haveliwala, Aristides Gionis, and Piotr Indyk (Stanford University)
- Clustering is one of the most crucial techniques for dealing with the massive amount of information present on the web. Clustering can either be performed once offline, independent of search queries, or performed online on the results of search queries. Our offline approach aims to efficiently cluster similar pages on the web, using the technique of Locality-Sensitive Hashing (LSH), in which web pages are hashed in such a way that similar pages have a much higher probability of collision than dissimilar pages. Our preliminary experiments on the Stanford WebBase have shown that the hash-based scheme can be scaled to millions of urls.
�
- Similarity Search on the Web: Evaluation and Scalability Considerations
(2001
), by Taher Haveliwala, Aristides Gionis, Dan Klein, and Piotr Indyk (Stanford Unversity)
- Allowing users to find pages on the web similar to a particular query page is a crucial component of modern search engines. A variety of techniques and approaches exist to support "Related Pages" queries. In this paper we discuss shortcomings of previous approaches and present a unifying approach that puts special emphasis on the use of text, both within anchors and surrounding anchors. In the central contribution of our paper, we present a novel technique for automating the evaluation process, allowing us to tune our parameters to maximize the quality of the results. Finally, we show how to scale our approach to millions of web pages, using the established Locality-Sensitive-Hashing technique.
- �
- Topic-Sensitive PageRank
(2002
), by Taher Haveliwala (Stanford University)
- In the original PageRank algorithm for improving the ranking of search-query results, a single PageRank vector is computed, using the link structure of the Web, to capture the relative "importance" of Web pages, independent of any particular search query. To yield more accurate search results, we propose computing a set of PageRank vectors, biased using a set of representative topics, to capture more accurately the notion of importance with respect to a particular topic. By using these (precomputed) biased PageRank vectors to generate query-specific importance scores for pages at query time, we show that we can generate more accurate rankings than with a single, generic PageRank vector. For ordinary keyword search queries, we compute the topic-sensitive PageRank scores for pages satisfying the query using the topic of the query keywords. For searches done in context (e.g., when the search query is performed by highlighting words in a Web page), we compute the topic-sensitive PageRank scores using the topic of the context in which the query appeared.
�
- Reliably Networking a Multicast Repository
(2001
), by Wang Lam and Hector Garcia-Molina (Stanford University)
- In this paper, we consider the design of a reliable multicast facility over an unreliable multicast network. Our multicast facility has several interesting properties: it has different numbers of clients interested in each data packet, allowing us to tune our strategy for each data transmission; has recurring data items, so that missed data items can be rescheduled for later transmission; and allows the server to adjust the scheduler according to loss information. We exploit the properties of our system to extend traditional reliability techniques for our case, and use performance evaluation to highlight the resulting differences. We find that our reliability techniques can reduce the average client wait time by over thirty percent.
�
- Crawling the Hidden Web
(2001
), by Sriram Raghavan and Hector Garcia-Molina (Stanford University)
- Current-day crawlers retrieve content only from the publicly indexable Web, i.e.,the set of web pages reachable purely by following hypertext links, ignoring search forms and pages that require authorization or prior registration. In particular, they ignore the tremendous amount of high quality content ``hidden'' behind search forms, in large searchable electronic databases. In this paper, we provide a framework for addressing the problem of extracting content from this hidden Web. At Stanford, we have built a task-specific hidden Web crawler called the Hidden Web Exposer (HiWE). We describe the architecture of HiWE and present a number of novel techniques that went into its design and implementation. We also present results from experiments we conducted to test and validate our techniques.
�
- Representing Web Graphs
(2002
), by Sriram Raghavan and Hector Garcia-Molina (Stanford University)
- A Web repository is a large special-purpose collection of Web pages and associated indexes. Many useful queries and computations over such repositories involve traversal and navigation of the Web graph. However, efficient traversal of huge Web graphs containing several hundred million vertices and a few billion edges is a challenging problem. This is further complicated by the lack of a schema to describe the structure of Web graphs. As a result, naive graph representation schemes can significantly increase query execution time and limit the usefulness of Web repositories. In this paper, we propose a novel representation for Web graphs, called an extit{S-Node representation}. We demonstrate that S-Node representations are highly space-efficient, enabling in-memory processing of very large Web graphs. In addition, we present detailed experiments that show that by exploiting some empirically observed properties of Web graphs, S-Node representations significantly reduce query execution times when compared with other schemes for representing Web graphs.
�
- Building a Distributed Full-Text Index for the Web
(2001
), by Sergey Melnik, Sriram Raghavan, Beverly Yang, and Hector Garcia-Molina (Stanford University)
- We identify crucial design issues in building a distributed inverted index for a large collection of web pages. We introduce a novel pipelining technique for structuring the core index-building system that substantially reduces the index construction time. We also propose a storage scheme for creating and managing inverted files using an embedded database system. We propose and compare different strategies for addressing various issues relevant to distributed index construction. Finally, we present performance results from experiments on a testbed distributed indexing system that we have implemented.
�
- Multicasting a Changing Repository
(2002
), by Wang Lam and Hector Garcia-Molina (Stanford University)
- Web crawlers generate significant loads on Web servers, and are difficult to operate. Instead of repeatedly running crawlers at many "client" sites, we propose a central crawler and Web repository that multicasts appropriate subsets of the central repository, and their subsequent changes, to subscribing clients. Loads at Web servers are reduced because a single crawler visits the servers, as opposed to all the client crawlers. In this paper we model and evaluate such a central Web multicast facility for subscriber clients, and for mixes of subscriber and one-time downloader clients. We consider different performance metrics and multicast algorithms for such a multicast facility, and develop guidelines for its design under various conditions.
�
- Hilltop: A Search Engine based on Expert Documents
(1999
), by Krishna Bharat (Compaq, Systems Research Center), George A. Mihaila (University of Toronto)
- In response to a query a search engine returns a ranked list of documents. If the query is broad (i.e., it matches many documents) then the returned list is usually too long to view fully. Studies show that users usually look at only the top 10 to 20 results. In this paper, we propose a novel ranking scheme for broad queries that places the most authoritative pages on the query topic at the top of the ranking. Our algorithm operates on a special index of "expert documents." These are a subset of the pages on the WWW identified as directories of links to non-affiliated sources on specific topics. Results are ranked based on the match between the query and relevant descriptive text for hyperlinks on expert pages pointing to a given result page. We present a prototype search engine that implements our ranking scheme and discuss its performance. With a relatively small (2.5 million page) expert index, our algorithm was able to perform comparably on broad queries with the best of the mainstream search engines.
�
- WebBase: A repository of Web pages
(2000
), by Jun Hirai, Sriram Raghavan, Andreas Paepcke, and Hector Garcia-Molina (Stanford University)
- In this paper, we study the problem of constructing and maintaining a large shared repository of web pages. We discuss the unique characteristics of such a repository, propose an architecture, and identify its functional modules. We focus on the storage manager module, and illustrate how traditional techniques for storage and indexing can be tailored to meet the requirements of a web repository. To evaluate design alternatives, we also present experimental results from a prototype repository called "WebBase", that is currently being developed at Stanford University
�
- Automatic Resource Compilation By Analyzing Hyperlink Structure and Associated Text
(1998
), by Soumen Chakrabarti, Byron Dom, Prabhakar Raghavan, Sridhar Rajagopalan (IBM Almaden Research Center K53), David Gibson (University of California, Berkeley), Jon Kleinberg (Cornell University)
- We describe the design, prototyping and evaluation of ARC, a system for automatically compiling a list of authoritative Web resources on any (sufficiently broad) topic. The goal of ARC is to compile resource lists similar to those provided by Yahoo! or Infoseek. The fundamental difference is that these services construct lists either manually or through a combination of human and automated effort, while ARC operates fully automatically. We describe the evaluation of ARC, Yahoo!, and Infoseek resource lists by a panel of human users. This evaluation suggests that the resources found by ARC frequently fare almost as well as, and sometimes better than, lists of resources that are manually compiled or classified into a topic. We also provide examples of ARC resource lists for the reader to examine.
|
|

|
Information Request
I would like to see a real site (and pricing) as well as information on availability for my area for lead generation.
|
|

|
|
|
GENERATE LEADS
LEARN MORE >>
First: We create an incredible website, breaking out up to 700 communities/suburbs/subdivisions, each with its own page!

Second: We offer TWO options for our clients. One allows you to simply post (or have us do this for you) to Craigslist a high impact flyer generated by any search on your site! What this means is that you can create searches in various popular areas, at price ranges you know are popular. We even allow you to create flyers based on FORECLOSURES / HUD / SHORT SALES etc!
This allows you to generate leads by your own SWEAT EQUITY! You aren't tied to a large monthly bill to generate leads! We're the only company on the internet that offers this!

Optionally: Adwords - We CREATE for you up to 1200 ADS (Each with over 40 keyword phrases) for up to 400 communities/neighborhoods/subdivisions Each with its own landing page! No more wasting money on clicks that go to a generic page that isn't really what the client wants! We drive the client to the page they were looking for so you generate a lead for about every 7-9 clicks! (on average)
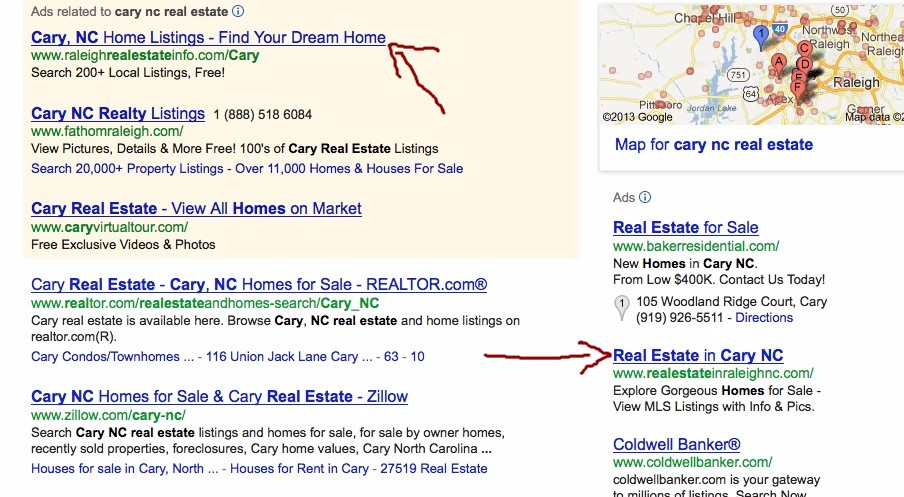
Third: We drive incoming traffic (potential clients) to a high impact (lead generating page) with lots of useful information and methods to capture leads Like View Just Listed, View Foreclosures, Answer a Question, Recently Reduced, Hot List and More!
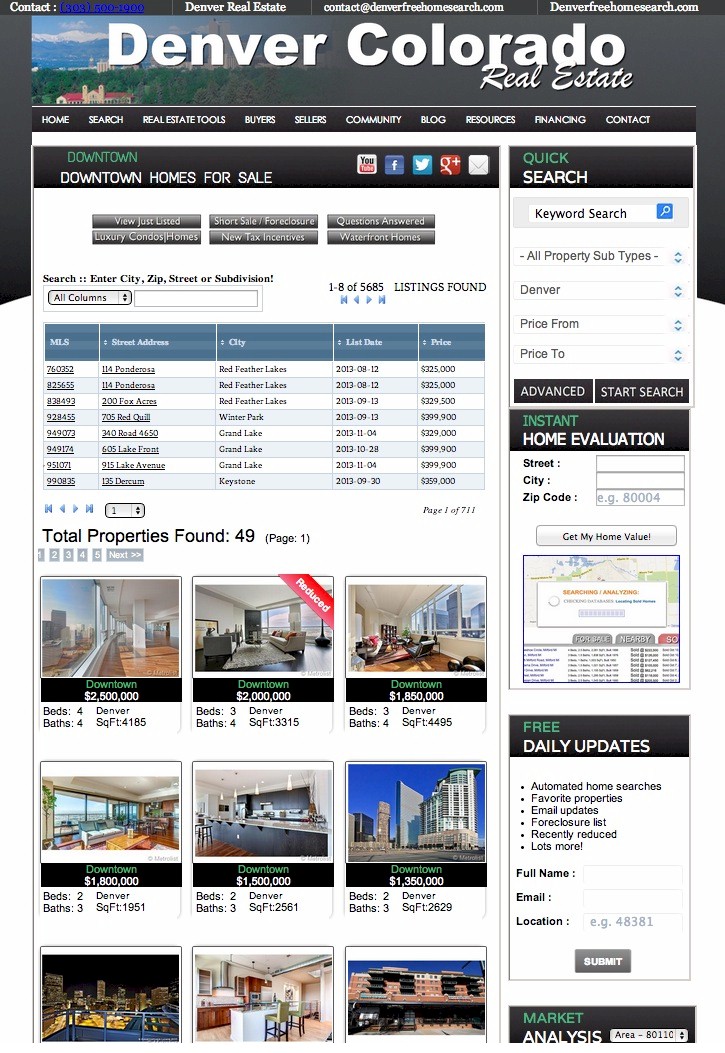 Finally: Once your generating leads (Day 1 if you're posting to craigslist!) You'll have a robust back end CRM system that will allow you to effectively manage your leads. Each time the visitor returns, they'll get an email thanking them for their return visit with different content written for each visit. You'll be able to see each page they visited and how long they stayed on each page. Advanced traffic analysis will let you know how many daily visitors you're receiving, which search engines are driving traffic to you and what keyword phrases are being used to find our site organically!
Finally: Once your generating leads (Day 1 if you're posting to craigslist!) You'll have a robust back end CRM system that will allow you to effectively manage your leads. Each time the visitor returns, they'll get an email thanking them for their return visit with different content written for each visit. You'll be able to see each page they visited and how long they stayed on each page. Advanced traffic analysis will let you know how many daily visitors you're receiving, which search engines are driving traffic to you and what keyword phrases are being used to find our site organically!
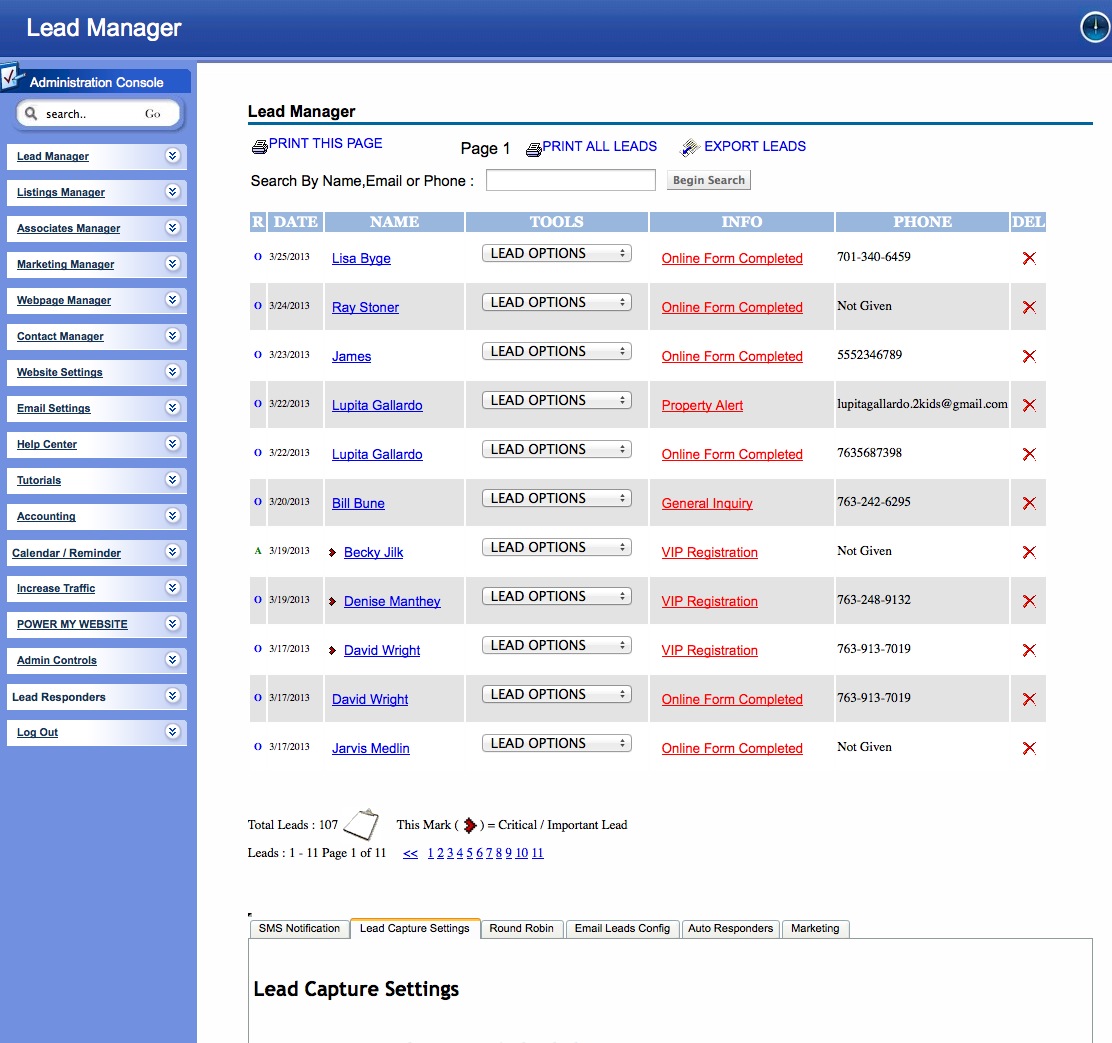
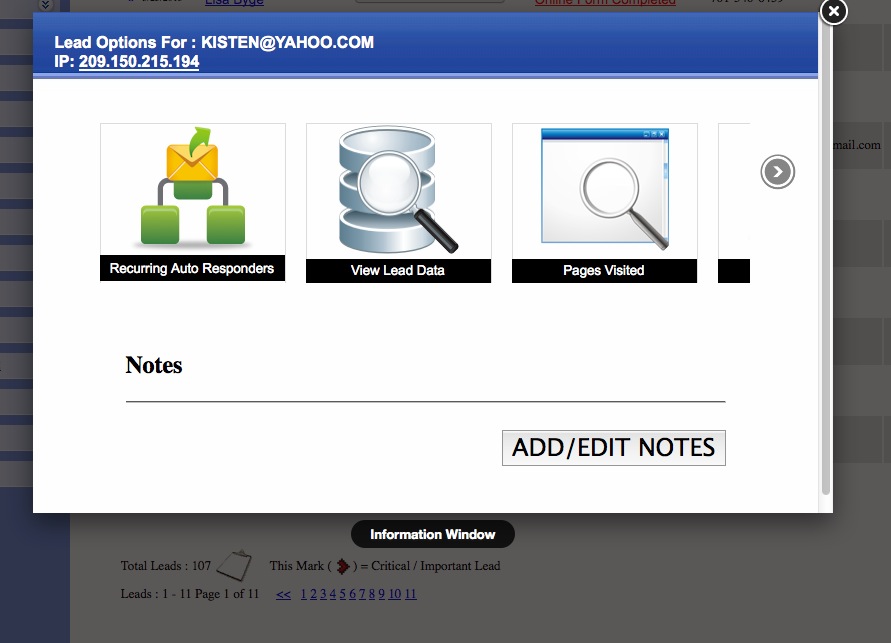
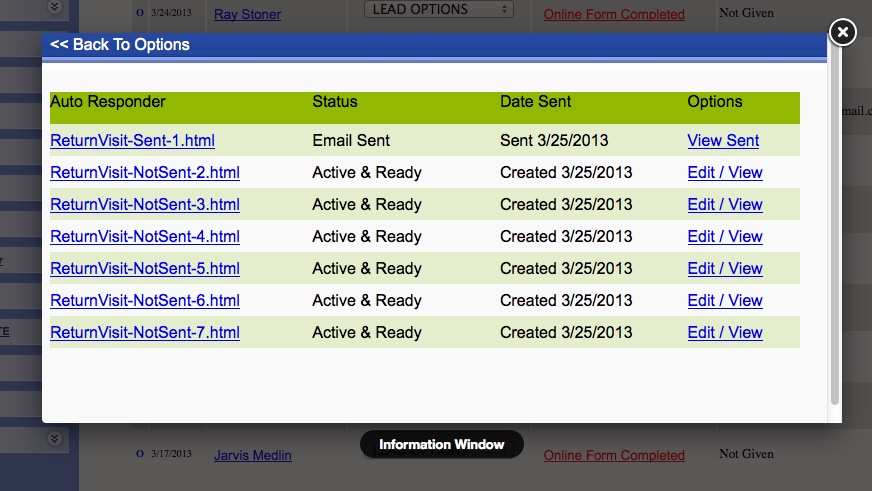
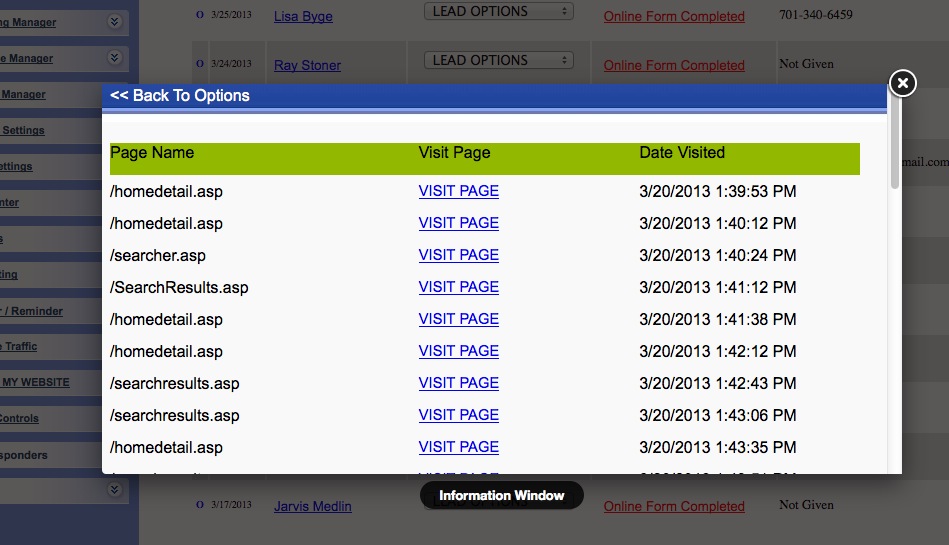

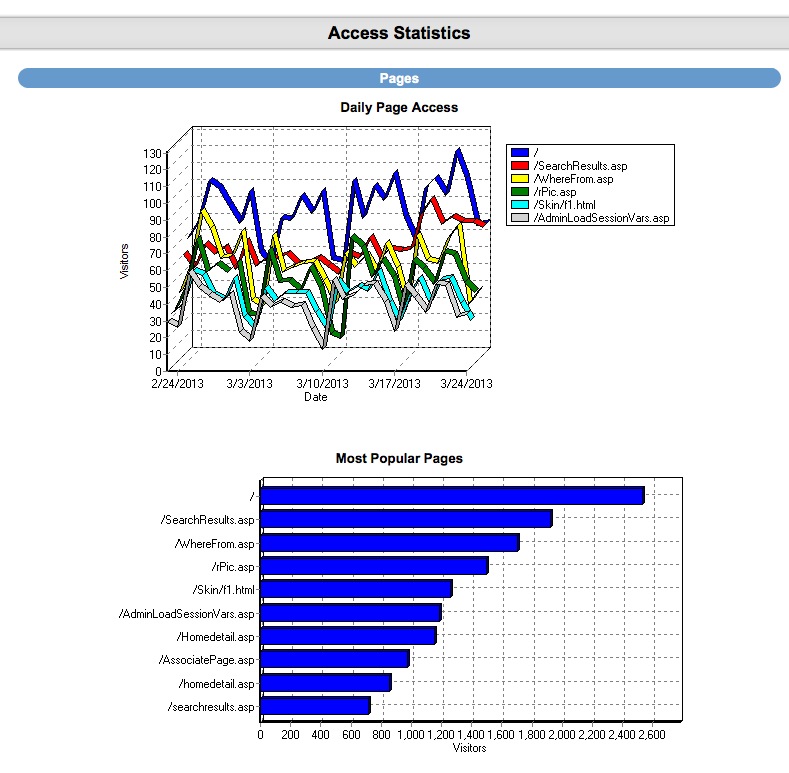
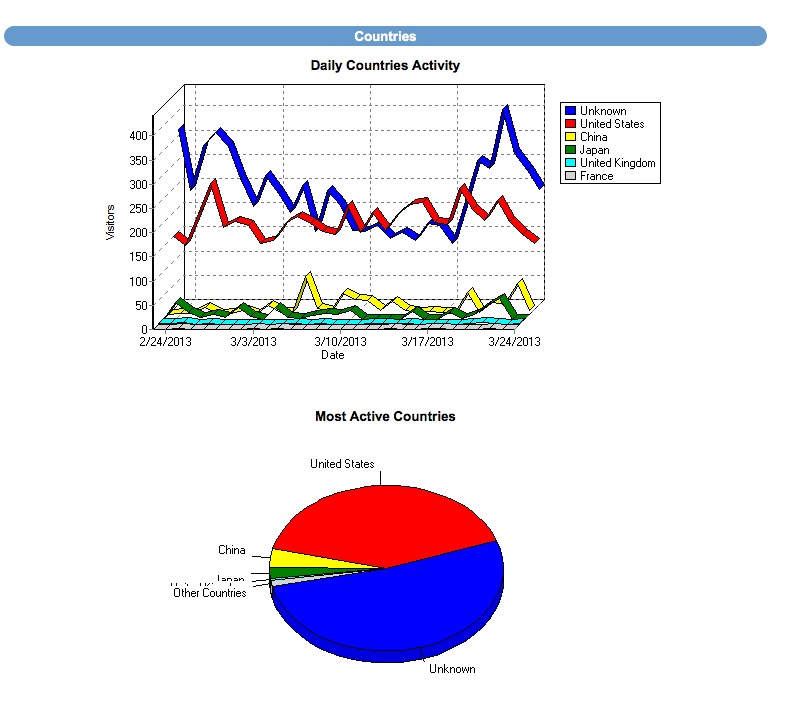
CRM also includes: Email Drip Marketing, Client login portal with saved listings, email a friend, private communication message base and document file system. Broker round robin sysetm is also built in! There are too many features to mention!
|
|
|
|
|
|
|
|
|
|
|
|
Top SEO Techniques
- Link Building - Quality Inbound Links
- Proper Text / Keyword Density (Title, Heading and Meta Tags)
- Image Tag Attribution
- Relavant Text Links
- Robust, regularly updated XML Sitemap
- Relavant, Consistant Content
- Easy Blogging (Our system will ask you questions)
- Social Media Hooks and Youtube Video Hooks
|
|
|
|
|