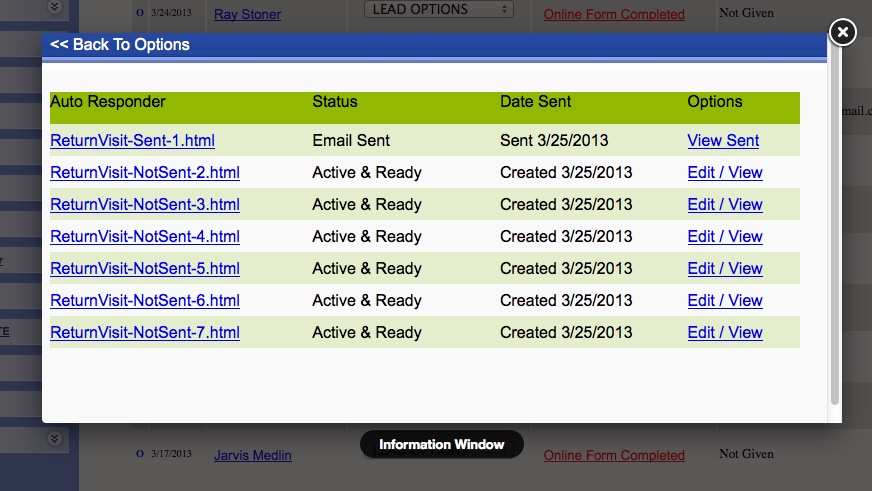
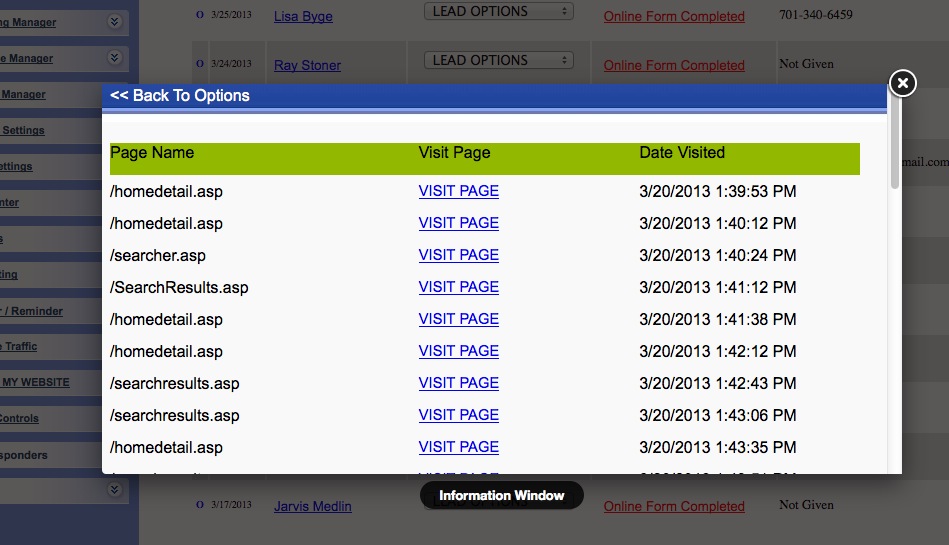
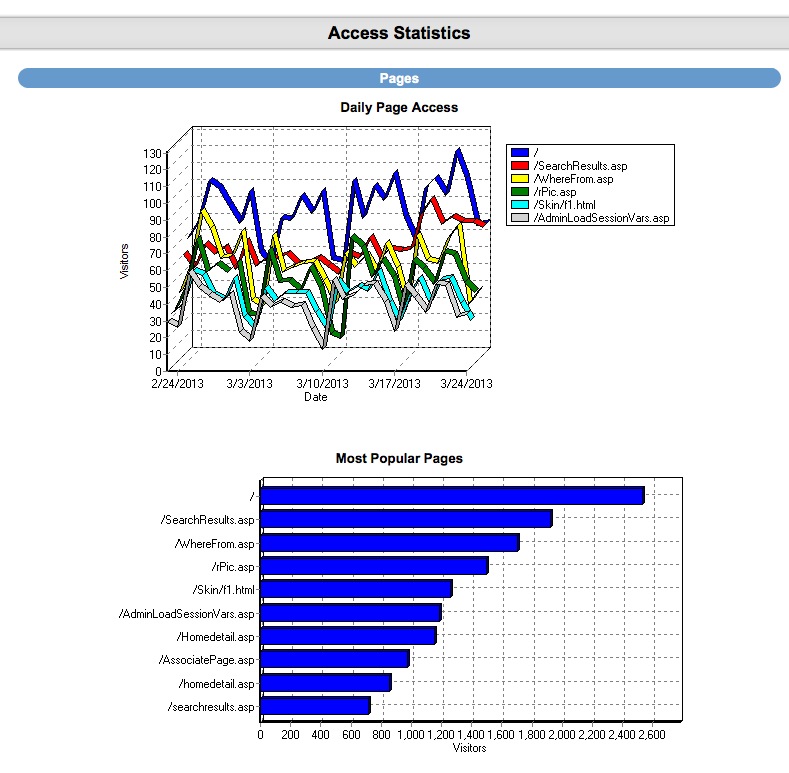
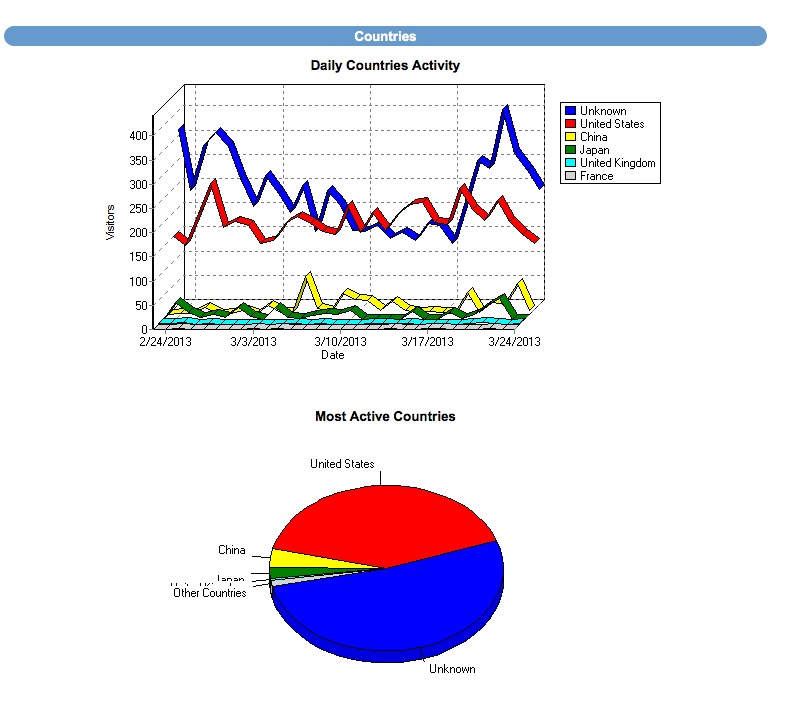
|
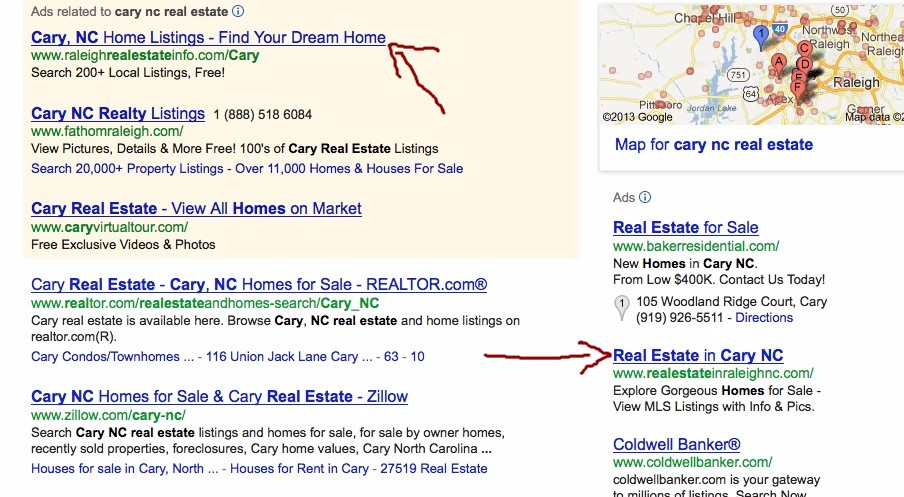
We all want our web site to get spidered
-� deep and often!
� But there are some areas you simply do not want spiders to visit.� That's where the robots.txt file comes in.� This important text file will not only keep private pages private, but will save the spider time crawling your site.
If the spider's.txt is properly constructed according to the rules
and displaced in the root directory, you're in business.
It should look like this.
User-agent: *
Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/
This would indicate to the robots that all robots are excluded from the.cgi/bin, /tmp/ and/~joe/ directories. This statement would keep all spiders from spidering the contents of your site:
User-agent: *
Disallow: /
and this statement would keep googlebot from spidering your email directory
:
User-agent:googlebot
Disallow: /email/
---------
The robots meta tag provides some of the functionality of the robots.txt file, but applies only to a particular page where it is located, whereas the robots.txt file applies to your entire site. The robots meta tags is formulated as:
This would prevent all well behaved robots from indexing this page and from analyzing it for links to follow.
It is not necessary to use a robots meta tag to instruct spiders to index the pages, since by default spiders will find and follow all links.
�
�
|